First we need to install mrjob with:
pip install mrjobI am starting with a simple example of word counting. Previously I implemented this directly using the hadoop streaming interface, therefore mapper and reducer were scripts that read from standard input and print to standard output, see mapper.py and reducer.py in:
https://github.com/zonca/python-wordcount-hadoop
With MrJob instead the interface is a little different, we implement the mapper method of our subclass of MrJob that already gets a “line” argument and yields the output as a tuple like (“word”, 1).
MrJob makes the implementation of the reducer particularly simple. Using hadoop-streaming directly, we needed also to first parse back the output of the mapper into python objects, while MrJob does it for you and gives directly the key and the list of count, that we just need to sum.
The code is pretty simple:
First we can test locally with 2 different methods, either:
or:
The first is a simple local test, the seconds sets some hadoop variables and uses multiprocessing to run the mapper in parallel.
https://github.com/zonca/python-wordcount-hadoop/blob/master/mrjob/word_count_mrjob.py
python word_count_mrjob.py gutemberg/20417.txt.utf-8
or:
python word_count_mrjob.py –runner=local gutemberg/20417.txt.utf-8
The first is a simple local test, the seconds sets some hadoop variables and uses multiprocessing to run the mapper in parallel.
Run on Amazon Elastic Map Reduce
Next step is submitting the job to EMR.
First get an account on Amazon Web Services from aws.amazon.com .
Setup MrJob with Amazon:
https://mrjob.readthedocs.io/en/latest/guides/emr-quickstart.html
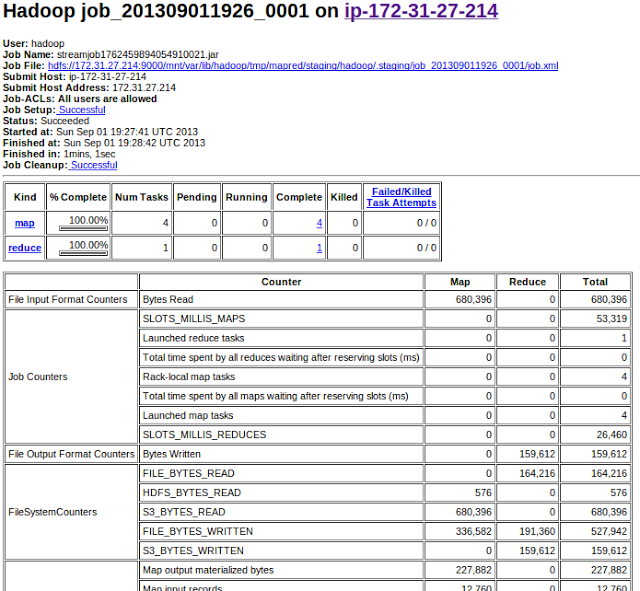
Once the job completes, MrJob copies the output back to the local machine, here are few lines from the file:
First get an account on Amazon Web Services from aws.amazon.com .
Setup MrJob with Amazon:
https://mrjob.readthedocs.io/en/latest/guides/emr-quickstart.html
Then we just need to choose the “emr” runner for MrJob to take care of:
- Copy the python module to Amazon S3, with requirements
- Copy the input data to S3
- Create a small EC2 instance (of course we could set it up to run 1000 instead)
- Run Hadoop to process the jobs
- Create a local web service that allows easy monitoring of the cluster
- When completed, copy the results back (this can be disabled to just leave the results on S3.
e.g.:
python word_count_mrjob.py –runner=emr –aws-region=us-west-2 gutemberg/20417.txt.utf-8
It is important to make sure that the aws-region used by MrJob is the same we used for creating the SSH key on the EC2 console in the MrJob configuration step, i.e. SSH keys are region-specific.
Logs and output of the run
MrJob copies the needed files to S3:
Therefore we can connect to that address to check realtime information about the cluster running on EC2, for example: Logs and output of the run
MrJob copies the needed files to S3:
. runemr.shCreates the instances:
using configs in /home/zonca/.mrjob.conf
using existing scratch bucket mrjob-ecd1d07aeee083dd
using s3://mrjob-ecd1d07aeee083dd/tmp/ as our scratch dir on S3
creating tmp directory /tmp/mrjobjob.zonca.20130901.192250.785550
Copying non-input files into s3://mrjob-ecd1d07aeee083dd/tmp/mrjobjob.zonca.20130901.192250.785550/files/
Waiting 5.0s for S3 eventual consistency
Creating Elastic MapReduce job flow
Job flow created with ID: j-2E83MO9QZQILB
Created new job flow j-2E83MO9QZQILB
Job launched 30.9s ago, status STARTING: Starting instancesCreates an SSH tunnel to the tracker:
Job launched 123.9s ago, status BOOTSTRAPPING: Running bootstrap actions
Job launched 250.5s ago, status RUNNING: Running step (mrjobjob.zonca.20130901.192250.785550: Step 1 of 1)
Opening ssh tunnel to Hadoop job tracker
Connect to job tracker at: http://localhost:40630/jobtracker.jsp
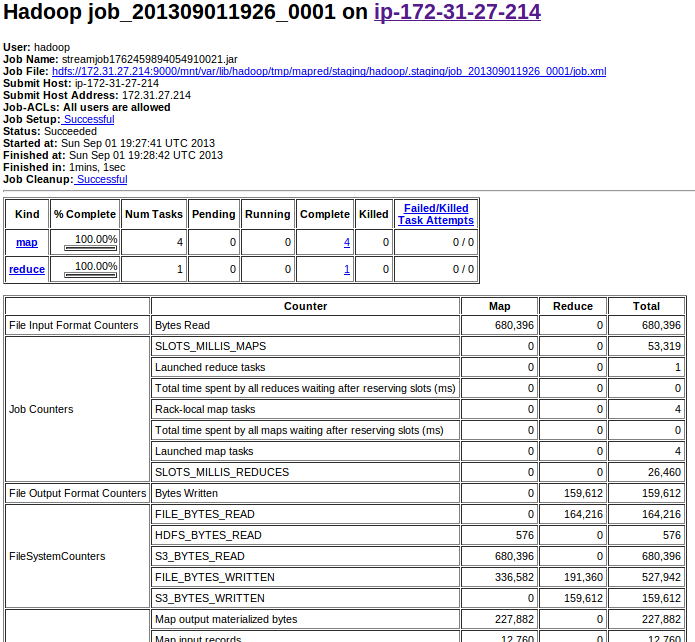
Once the job completes, MrJob copies the output back to the local machine, here are few lines from the file:
“maladies” 1
“malaria” 5
“male” 18
“maleproducing” 1
“males” 5
“mammal” 10
“mammalInstinctive” 1
“mammalian” 4
“mammallike” 1
“mammals” 87
“mammoth” 5
“mammoths” 1
“man” 152
I’ve been positively impressed that it is so easy to implement and run a MapReduce job with MrJob without need of managing directly EC2 instances or the Hadoop installation.
This same setup could be used on GB of data with hundreds of instances.